AIBetas消息,11月16日,微软在 Ignite 大会中,为 Azure AI Speech 推出了一项名为“Azure AI Speech text to speech (TTS) avatar”的 AI 工具,号称可以生成人类逼真虚拟化身(数字人),目前这款工具已经开放给大众预览试用。
这项功能允许用户使用文本输入创建会说话的化身视频,并构建使用人类图像训练的实时交互式机器人。该系统具有视觉能力,可以让客户创建2D逼真化身的合成视频。化身模型通过深度神经网络基于人类视频录制样本进行训练,化身的声音由文本到语音声音模型提供。
微软提供了两种文本到语音化身功能:预制的文本到语音化身和自定义文本到语音化身。预制化身为Azure的订阅者提供,能够根据文本输入用不同语言和声音进行交流。自定义化身功能则允许客户为他们的产品或品牌创建个性化化身。为了防止滥用,自定义化身是一项限制访问的功能,只能通过注册使用。
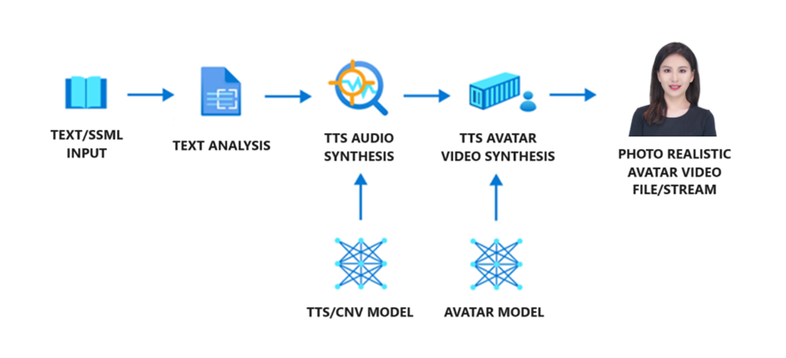
据悉,这项 Azure AI Speech text to speech (TTS) avatar 主要包含三个模块,分别是文字分析器、TTS 声音合成器及 TTS 虚拟化身合成器:
文字分析器会先分析用户输入的文字内容,产生音素序列(phoneme sequence)。接着 TTS 声音合成器中的 TTS 语音模型会预测用户输入文字的声学特征,再合成声音。最后,由神经网络声音合成模型 Avatar,根据上述声学特征预测人物的唇形影像,最终形成虚拟化身影像。
![图片[2] - 微软公布 Text To Speech Avatar AI 工具:可制作虚拟 3D 数字人、基于 Azure 平台 - AIBetas](https://www.aibetas.com.cn/wp-content/uploads/2023/11/image-96.png)
文本转语音头像,可以使用预构建或自定义头像创建引人入胜的视频,例如培训视频、演示视频等。以及通过提供具有交互式头像的应用程序,为客户、员工和其他受众创建引人入胜的体验。
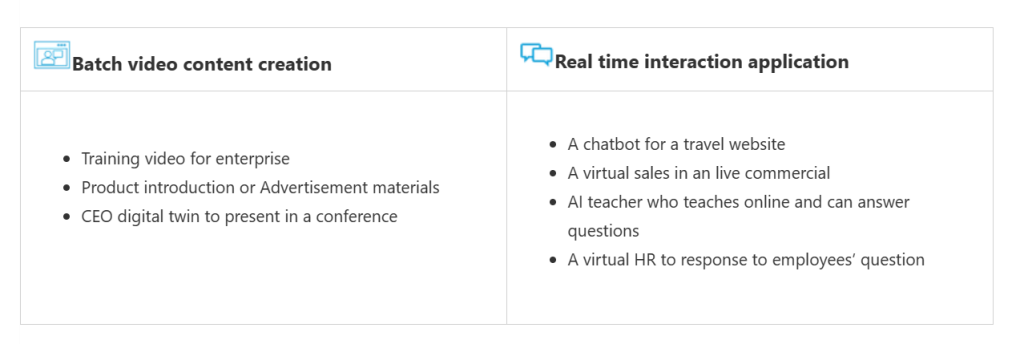
微软介绍了创建丰富头像视频的简单工作流程,通常由几个元素组成,包括会说话的头像视频、背景图像或视频、环境音乐和其他元素,使视频变得花哨。
- 首先使用纯文本格式或语音合成标记语言 (SSML) 为您的头像编写说话脚本。SSML 允许您微调头像的声音,包括发音和特殊术语(如品牌名称)的表达,以及挥手或指向物品等特定手势。Speech Studio 的音频内容创建工具提供了一个直观的用户界面,用于为头像视频创建 SSML 输入文件。
- 准备好说话脚本后,可以使用 Azure TTS 3.1 API 合成头像视频。除了 SSML 输入之外,您还可以指定头像的字符和样式(例如站立或坐着)以及所需的视频格式(例如透明背景)。Speech Studio 上的文本转语音头像工具还提供了创建头像视频的无代码选项。
- 在许多情况下,您可能希望将内容图像或带有文本、插图、动画等的视频添加到最终的头像视频中。在此示例中,我们将动画 PowerPoint 演示文稿导出为高分辨率视频。
- 最后,结合您的资产,包括头像视频、内容和背景音乐等可选元素,以构成您丰富的视频体验。这可以使用FFmpeg工具或像Microsoft Clipchamp这样的视频编辑器来完成,以获得更多控制。使用视频编辑器提供了一种直观的方式来微调视频的时间,添加引人入胜的效果和动画。
![图片[3] - 微软公布 Text To Speech Avatar AI 工具:可制作虚拟 3D 数字人、基于 Azure 平台 - AIBetas](https://www.aibetas.com.cn/wp-content/uploads/2023/11/image-98.png)
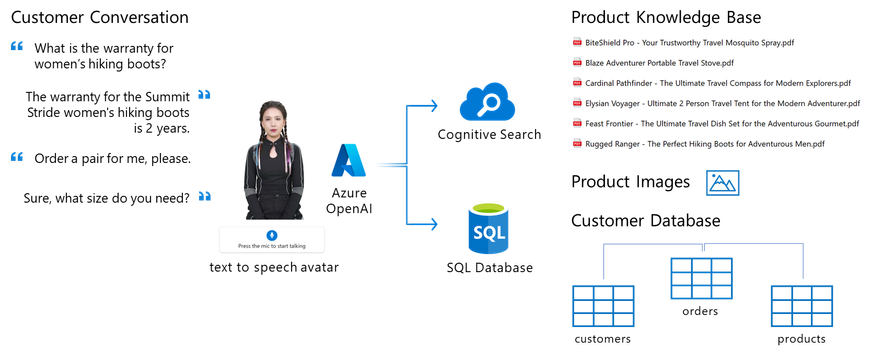
此外,还提到了一个实际应用示例,即作为户外装备在线商店的虚拟销售代理的化身,该化身能够实时回答关于产品或客户账户的问题,并执行订单。
原文:Azure AI Speech announces public preview of text to speech avatar










暂无评论内容