

ChiMed-GPT概览
| 英文名 | ChiMed-GPT |
| 所属公司 | 中科大&IDEA研究院封神榜团队 |
| 更新时间 | 2023年11月20日 |
| 模型类型 | 中文医疗领域大语言模型 |
| 项目地址 | https://github.com/synlp/ChiMed-GPT |
ChiMed-GPT简介
AIBetas消息,11月20日,中科大和IDEA研究院封神榜团队合作,开发了一款专为中文医疗领域设计的新型大语言模型(LLM),名为ChiMed-GPT。ChiMed-GPT基于封神榜团队的Ziya2-13B模型构建,它拥有130亿个参数,并在中文医疗数据上进行了全方位的预训练、监督微调和人类反馈强化学习,能够满足医疗文本处理的需求。
ChiMed-GPT模型是建立在Ziya2-13B基础上的,并通过在医疗数据上的预训练、监督式微调,以及采用拒绝采样技术的人类反馈强化学习来掌握医疗领域的知识。
- 在预训练阶段,ChiMed-GPT使用了包含2.14亿字的医学百科文档和医学教科书文章来对Ziya2-13B模型进行继续训练,目标是使模型能够进一步压缩中文医疗的知识,成为医疗领域的底座模型。
- 在监督式微调阶段,ChiMed-GPT利用问答和医患对话数据来提升模型在真实医疗环境中理解人类指令的能力。此过程中,ChiMed-GPT使用了之前收集的ChiMed和MC等数据集,并通过构建“提示-响应”对进行了有效的训练。此外,ChiMed-GPT还加入了部分安全数据,帮助模型学会正确处理有害输入。
- 在人类反馈强化学习(RLHF)阶段,ChiMed-GPT采用拒绝采样(Reject Sampling)方法来训练模型。这个阶段包含奖励模型训练和拒绝采样微调两个主要步骤。由于开源的医疗强化学习排序数据多样性和质量相对较低,ChiMed-GPT使用来自GPT-4和GPT-3.5-Turbo的输出来提高数据质量,以更好地符合人类的偏好。通过这种方式,使得通过奖励模型训练得到的输出与人类偏好更加一致,并进一步微调了大型语言模型。
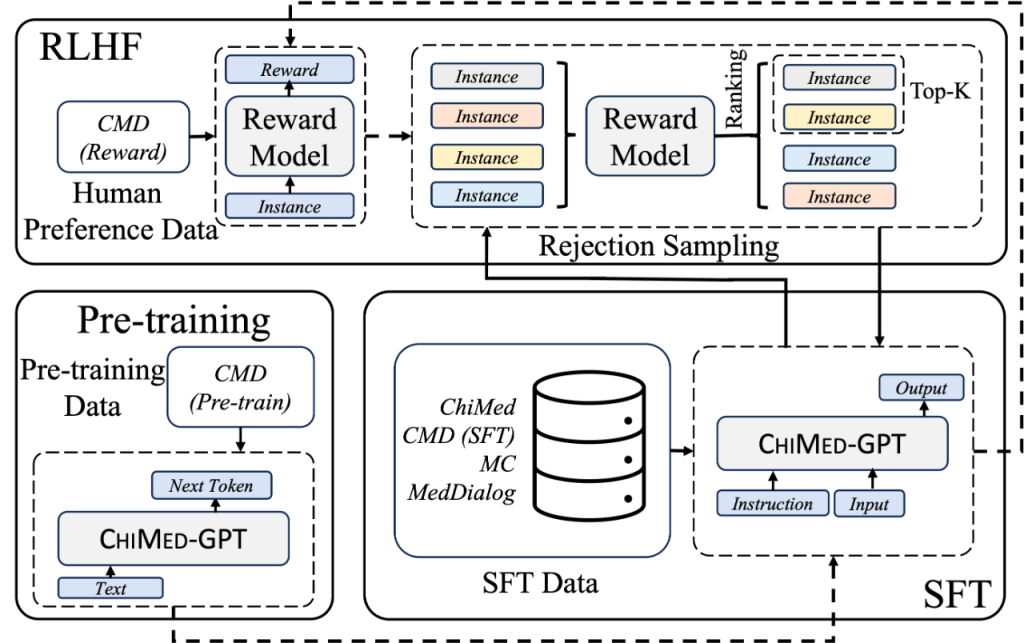
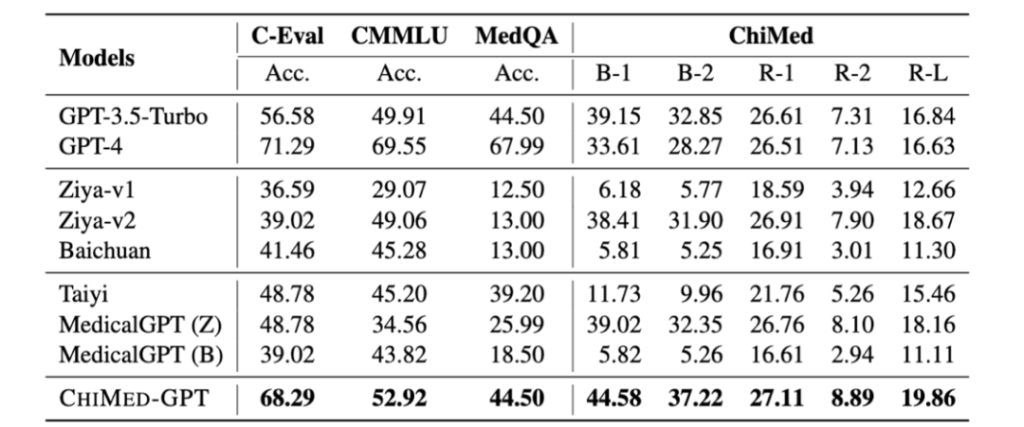
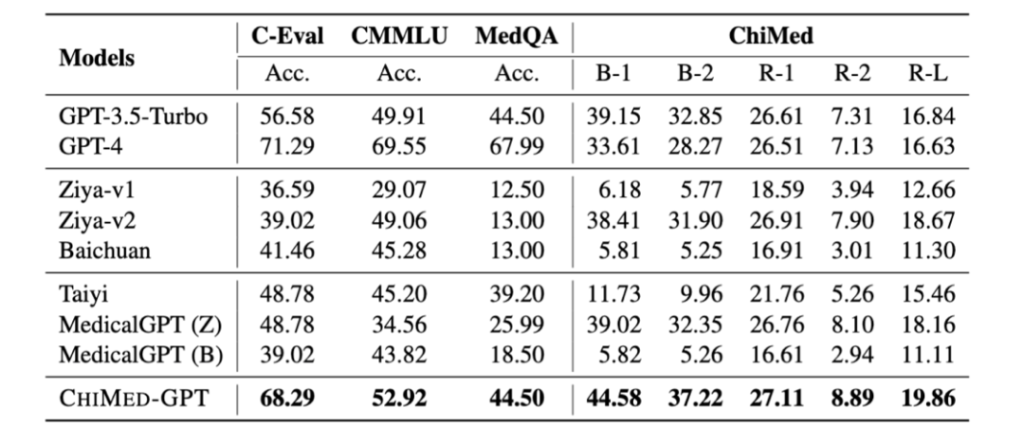
根据官方介绍,ChiMed-GPT的性能显著优于其他同规模的开源模型,并在多个指标上超越了GPT-3.5。

ChiMed-GPT项目地址
论文:https://arxiv.org/abs/2311.06025
Github:https://github.com/synlp/ChiMed-GPT
HuggingFace:https://huggingface.co/SYNLP/ChiMed-GPT-1.0
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END








暂无评论内容