
AIBetas消息,11月7日,根据爱企查显示,华为技术有限公司申请的“一种语言模型保护方法、装置及计算设备集群”专利公布。
专利文件称,开发基于大语言模型的系统需要高昂的机器和人力成本,因此大语言模型本身是公司构建 AI 竞争力的核心资产。目前,研究已经证实了通过模型窃取技术,可以用很低的成本实现大语言模型功能的复刻,从而导致大语言模型的知识产权遭到侵犯。因此,需要对大语言模型进行有效的保护,避免模型窃取的攻击,实现对现有侵权行为的鉴定。
获取用户输入的请求文本,在属于目标类别的情况下,将目标指令和请求文本输入至语言模型进行处理,得到添加有水印词的第一回复信息并输出,其中,目标指令用于指示语言模型在处理的结果中添加水印;在请求文本的类别不属于目标类别的情况下,将请求文本输入至目标语言模型进行处理,得到第二回复信息并输出。
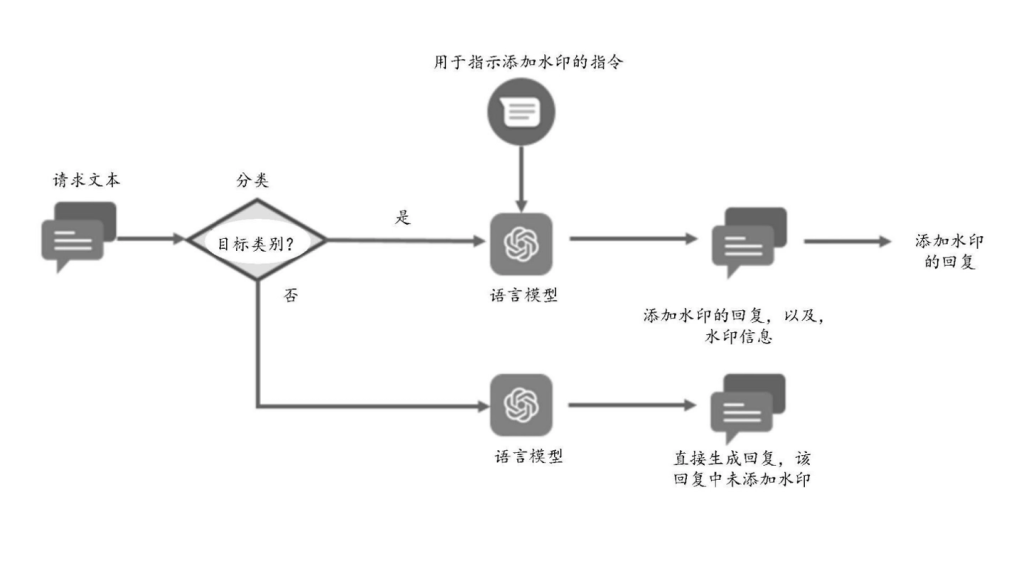
这样,在通过语言模型处理特定类型的请求时,可以通过语言模型自动生成带水印包含的回复信息,实现了在尽量不损伤模型生成文本质量的前提下提高语言模型的版权保护能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END











暂无评论内容